Web as data and web scraping tools
Disclaimer: Web scraping or web harvesting is an activity to extract data from the Web. There are various approaches like crawling the entire websites using web crawler, cURL, Heritrix, and etc. However, in this blog post, I am focusing more on how to extract certain data elements from the Web using XPath or CSS selectors.
Recently, I read two articles - one is about comparison between female and male scholars to attain public recognition (Schellekens, Holstege, & Yasseri, 2019) while the other is about Word Sense Disambiguation (WSD) (Segonne, Candito, & Crabblé, 2019). They are not related at all in terms of topic, but one thing I found quite fascinating was their research methods - both studies collected their datasets from the Web.
Schellekens et al. would like to answer their fundamental research question - why are there fewer Wikipedia entries about female scientists? In order to answer this question, they collected their datasets from three different web sources - Google Scholar for scientific accomplishment, genderize.io for gender, and Wikipedia for public recognition. The study was analyzed with logistic regression to see if there was a relationship between gender and Wikipedia recognition, controlling for h-index. The authors found strong evidence of discrimination between female and male scholars in public recognition of their scientific achievement.
Segonne et al. explore the use of Wiktionary which is an open-source, collaboratively edited multilingual online dictionary for Word Sense Disambiguation (WSD) in French. According to the authors, WSD is difficult to be conducted other than English due to costly sense annotated resources. However, they propose Wiktionary as their datasets to perform WSD other than English. They test Wiktionary with French and the results indicate that Wiktionary sense inventory contains a good quality sense annotation.
When I took research methods courses, I learned sort of traditional research methods - interviews, surveys, field studies and etc. They are still valid and very helpful, but Stephens (2017) argues in his book, Everybody lies: Big data, new data, and what the Internet can tell us about who we really are, that much of the new information these days flows from the Web - Google, social media, and etc. and this information allows researchers to finally investigate “what people want and really do, not what they say they want and say they do”.
Web scraping tools
The World Wide Web has become a source of data and information for daily activities and scientific research. For example, my colleague - Cecilia Tellis - Head, Design and Outreach at the uOttawa Library came up with an idea to use uoCal data to identify where and when most events on campus happened or it is cumbersome to manually copy and paste information from the Web. Some websites provide APIs to facilitate data exchange like MediaWiki API and E-utilities provided by NCBI (National Center for Biotechnology Information) or ways to download datasets from the Web like CSV and XML formats. However, most of the Web are still written in plain HTML and there is no way to download datasets other than web scraping. I would like to share some of the web scraping tools that I found very useful for daily work and research.
1. Google Sheets
I learned the IMPORTXML (url, xpath_query) function from my colleague, Mairelys Lemus-Rojas. This function allows you to import data from any structured data types (XML, HTML, CSV, TSV, RSS, and ATOM XML). It is really simple to use and useful if there are datasets that you’d like to import from one single page.
There is one project I am working with her and I would like to know if Wikidata entries about women and hosting institutions from the collection of Canadian Archive of Women in STEM existed. The portal was developed based on Drupal, so the way this information is structured is Drupal Fields.
HTML structure to display the title of archival fonds
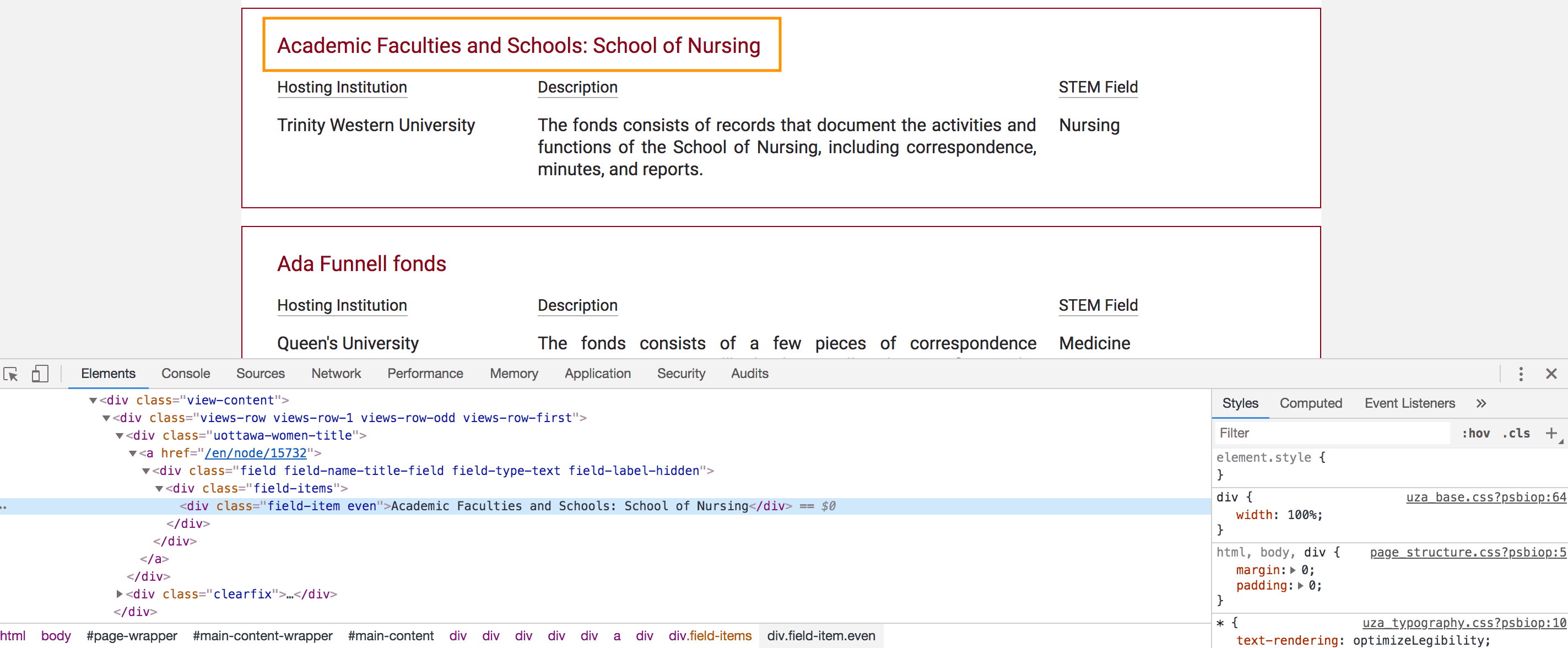
importxml("https://biblio.uottawa.ca/en/women-in-stem","//div[@class='field field-name-title-field field-type-text field-label-hidden']/div[@class='field-items']/div[@class='field-item even']"importxml("https://biblio.uottawa.ca/en/women-in-stem","//div[@class='field field-name-uottawa-women-organization field-type-text field-label-hidden']/div[@class='field-items']/div[@class='field-item even']")I was able to download all archival fonds and its corresponding hosting institutions in Google Sheets.
Then, I imported it to RStudio with googlesheets R package and ran a script using WikidataR package to find out how many entries were already available. When I did on May 15, there were 67 women and organizations in STEM and 279 hosting institutions available in Wikidata out of 296 records. It took me only 5 - 10 minutes from importing datasets from the Web to identifying how many Wikidata entries existed. I found that IMPORTXML is very simple but efficient for my daily activities.
2. RCrawler
RCrawler is one of my favourite R packages. RCrawler provides a lot of useful features, but one thing I found most useful is to extract structured data from all website pages, not just single page. I applied RCrawler for some of the projects - Data Migration to Open Journal Systems (OJS) using R with my colleague, Jeanette Hatherill - Scholarly Communications Librarian and Using web data for evidence-informed event management with R with Cecilia Tellis.
Like IMPORTXML, you can extract certain datasets using structured format from the entire webpages with ContentScraper(Url, XpathPatterns or CssPatterns, PatternsName). For example, Cecilia and I wanted to extract event title, start and end dates, event category, event organizer, location, and room.
urllist <- lapply(x, function(x) {
uocal_url <- paste("https://uocal.uottawa.ca/en/node/",x,"/",sep='');
return(uocal_url)
})ContentScraper(Url=urllist, XpathPatterns=c("//h1[@id='page-title']",
"//span[@class='date-display-start']/text()",
"//span[@class='date-display-end'/text()]",
"//a[contains(@href, 'field_event_type')][1]/text()",
"//a[contains(@href, 'field_event_organization')][1]/text()",
"//a[contains(@href, '/en/map')]/text()",
"//div[@class='field field-name-field-event-roomnum field-type-text field-label-inline clearfix']/*/div[@class='field-item even']/text()"),
PatternsName = c("Title", "Start", "End", "SingleDate", "ET1", "EO1", "Location", "Room"))There are several packages in R and Python for web scraping, but the logic and basic concept are very similar. Currently I am exploring other tools in Python with Jupyter Notebook to analyze and visualize Twitter data with Tweepy and data from Yelp about Korean restaurants, ranks, and review with Requests and Beautiful Soup.
Concerns about web data
I love to try new methodologies and download datasets from the Web for fun using either APIs or scraping tools. However, the speech at the Code4Lib 2019 by Tara Robertson gave me something to think about - consent and ethics (her talk was truly inspiring). She gave some examples with digitization projects, but consent and ethics should be applied and carefully examined for the Web data. Is it legal and ethical to collect data from the Web? Where can I get consent and from who? To be honest, I don’t know 100% sure, but now I am trying to learn from experts and think multiple times if there is something which could be harmful to anyone. Hope that one day I can write more about this topic related to using web data.
References
-
Schellekensa, M. H., Holstegeb, F., & Yasseri, T. (2019). Female scholars need to achieve more for equal public recognition. arXiv preprint arXiv:1904.06310 https://arxiv.org/abs/1904.06310.
-
Segonne, V., Candito, M., & Crabbé, B. (2019). Using Wiktionary as a Resource for WSD. Proceedings of the 13th International Conference on Computational Semantics. https://www.aclweb.org/anthology/W19-0422
-
Stephens-Davidowitz, S., & Pinker, S. (2017). Everybody lies: Big data, new data, and what the Internet can tell us about who we really are.